Using Python to Upload Data to Website
How to: Automate live data to your website with Python

This tutorial volition be helpful for people who have a website that hosts live data on a deject service but are unsure how to completely automate the updating of the alive information and then the website becomes hassle free. For instance: I host a website that shows Texas COVID example counts past canton in an interactive dashboard, just everyday I had to run a script to download the excel file from the Texas COVID website, clean the information, update the pandas data frame that was used to create the dashboard, upload the updated data to the cloud service I was using, and reload my website. This was annoying, then I used the steps in this tutorial to show how my live data website is now totally automated.
I will only be going over how to do this using the deject service pythonanywhere, but these steps can be transferred to other cloud services. Another thing to note is that I am new to edifice and maintaining websites and then please feel free to correct me or requite me effective feedback on this tutorial. I will be assuming that you lot have basic knowledge of python, selenium for web scraping, bash commands, and you have your ain website. Lets get through the steps of automating alive data to your website:
- web scraping with selenium using a cloud service
- converting downloaded data in a .part file to .xlsx file
- re-loading your website using the os python package
- scheduling a python script to run every day in pythonanywhere
I will not be going through some of the code I will be showing because I use much of the same code from my last tutorial on how to create and automate an interactive dashboard using python plant here. Lets get started!
- web scraping with selenium using a cloud service
So in your deject service of pick (mine existence pythonanywhere), open up up a python3.7 console. I volition be showing the lawmaking in chunks but all the code tin be combined into one script which is what I have done. Likewise, all the file paths in the code you volition have to change to your own for the code to work.
from pyvirtualdisplay import Brandish
from selenium import webdriver
import time
from selenium.webdriver.chrome.options import Options with Brandish():
# we can now start Firefox and it will run inside the virtual display
browser = webdriver.Firefox() # these options allow selenium to download files
options = Options()
options.add_experimental_option("browser.download.folderList",2)
options.add_experimental_option("browser.download.manager.showWhenStarting", Faux)
options.add_experimental_option("browser.helperApps.neverAsk.saveToDisk", "application/octet-stream,awarding/vnd.ms-excel") # put the residuum of our selenium lawmaking in a try/finally
# to make sure we always make clean upward at the terminate
try:
browser.get('https://world wide web.dshs.texas.gov/coronavirus/additionaldata/') # initialize an object to the location on the html folio and click on it to download
link = browser.find_element_by_xpath('/html/body/course/div[4]/div/div[3]/div[ii]/div/div/ul[one]/li[1]/a')
link.click() # Wait for 30 seconds to allow chrome to download file
time.sleep(30) print(browser.title)
finally:
browser.quit()
In the clamper of lawmaking above, I open up a Firefox browser within pythonanywhere using their pyvirtualdisplay library. No new browser volition pop on your computer since its running on the cloud. This means you should exam out the script on your own calculator without the brandish() function because error handling will be difficult within the cloud server. Then I download an .xlsx file from the Texas COVID website and it saves information technology in my /tmp file inside pythonanywhere. To access the /tmp file, just click on the kickoff "/" of the files tab that gain the domicile file push button. This is all done within a attempt/finally blocks, so after the script runs, we close the browser and so we exercise non use any more cpu fourth dimension on the server. Another thing to note is that pythonanywhere only supports one version of selenium: 2.53.half-dozen. Yous can downgrade to this version of selenium using the following fustigate control:
pip3.7 install --user selenium==two.53.vi 2. converting downloaded data in a .part file to .xlsx file
import shutil
import glob
import os # locating almost recent .xlsx downloaded file
list_of_files = glob.glob('/tmp/*.xlsx.part')
latest_file = max(list_of_files, key=bone.path.getmtime)
print(latest_file) # we need to locate the old .xlsx file(s) in the dir nosotros want to shop the new xlsx file in
list_of_files = glob.glob('/dwelling/tsbloxsom/mysite/get_data/*.xlsx')
impress(list_of_files) # need to delete sometime xlsx file(southward) so if we download new xlsx file with same name we do not get an fault while moving information technology
for file in list_of_files:
print("deleting old xlsx file:", file)
bone.remove(file) # move new data into information dir
shutil.move("{}".format(latest_file), "/home/tsbloxsom/mysite/get_data/covid_dirty_data.xlsx")
When you download .xlsx files in pythonanywhere, they are stored every bit .xlsx.role files. After some research, these .role files are acquired when you lot stop a download from completing. These .part files cannot be opened with typical tools simply there is a easy trick around this problem. In the above code, I automate moving the new information and deleting the former data in my deject directories. The part to detect is that when I motility the .xlsx.part file, I salvage information technology as a .xlsx file. This converts it magically, and when you open this new .xlsx file, it has all the live data which means that my script did download the complete .xlsx file but pythonanywhere adds a .office to the file which is weird but hey it works.
3. re-loading your website using the bone python parcel
import pandas as pd
import re list_of_files = glob.glob('/home/tsbloxsom/mysite/get_data/*.xlsx')
latest_file = max(list_of_files, key=os.path.getctime)
impress(latest_file) df = pd.read_excel("{}".format(latest_file),header=None) # print out latest COVID data datetime and notes
date = re.findall("- [0-9]+/[0-nine]+/[0-9]+ .+", df.iloc[0, 0])
print("COVID cases latest update:", date[0][2:])
print(df.iloc[1, 0])
#print(str(df.iloc[262:266, 0]).lstrip().rstrip()) #drop non-data rows
df2 = df.drop([0, 1, 258, 260, 261, 262, 263, 264, 265, 266, 267]) # make clean column names
df2.iloc[0,:] = df2.iloc[0,:].utilise(lambda x: 10.supervene upon("\r", ""))
df2.iloc[0,:] = df2.iloc[0,:].apply(lambda x: x.replace("\n", ""))
df2.columns = df2.iloc[0]
clean_df = df2.drop(df2.index[0])
clean_df = clean_df.set_index("County Proper noun") clean_df.to_csv("/domicile/tsbloxsom/mysite/get_data/Texas county COVID cases information clean.csv") df = pd.read_csv("Texas county COVID cases data make clean.csv") # catechumen df into time series where rows are each date and make clean up
df_t = df.T
df_t.columns = df_t.iloc[0]
df_t = df_t.iloc[1:]
df_t = df_t.iloc[:,:-2] # next lets convert the alphabetize to a date fourth dimension, must make clean upwards dates first
def clean_index(southward):
south = s.replace("*","")
s = s[-5:]
south = s + "-2020"
#print(southward)
return due south df_t.index = df_t.index.map(clean_index) df_t.index = pd.to_datetime(df_t.alphabetize) # initalize df with three columns: Date, Case Count, and County
anderson = df_t.T.iloc[0,:] ts = anderson.to_frame().reset_index() ts["County"] = "Anderson"
ts = ts.rename(columns = {"Anderson": "Example Count", "index": "Date"}) # This while loop adds all counties to the above ts so we can input information technology into plotly
x = i
while 10 < 254:
new_ts = df_t.T.iloc[x,:]
new_ts = new_ts.to_frame().reset_index()
new_ts["Canton"] = new_ts.columns[1]
new_ts = new_ts.rename(columns = {new_ts.columns[1]: "Case Count", "alphabetize": "Engagement"})
ts = pd.concat([ts, new_ts])
x += 1 ts.to_csv("/home/tsbloxsom/mysite/data/time_series_plotly.csv") time.sleep(5) #reload website with updated data
os.utime('/var/www/tsbloxsom_pythonanywhere_com_wsgi.py')
Most of the in a higher place lawmaking I explained in my last post which deals with cleaning excel files using pandas for inputting into a plotly dashboard. The most important line for this tutorial is the very last one. The os.utime function shows admission and change times of a file or python script. Only when yous call the function on your Web Server Gateway Interface (WSGI) file it volition reload your website!
iv. scheduling a python script to run every day in pythonanywhere
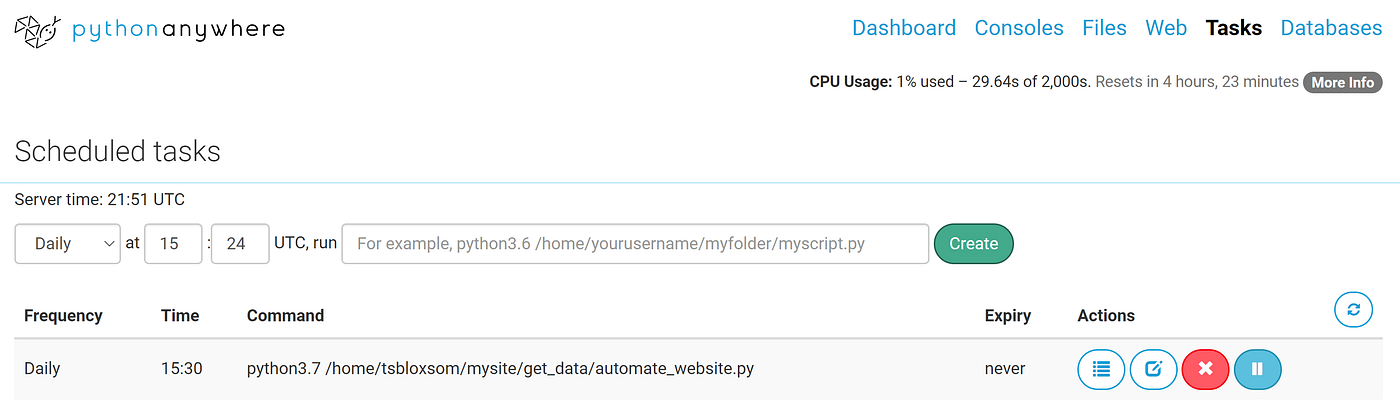
At present for the easy function! After you combine the above code into one .py file, you lot tin brand it run every day or hr using pythonanywhere'south Task tab. All you practice is copy and paste the bash command, with the total directory path, you would utilise to run the .py file into the bar in the image above and hitting the create button! Now you should test the .py file using a bash console starting time to see if it runs correctly. But now you take a fully automated data scraping script that your website can utilize to have daily or hourly updated data displayed without you having to push button one push button!
If you have whatever questions or critiques please feel free to say so in the comments and if you want to follow me on LinkedIn you tin!
Source: https://towardsdatascience.com/how-to-automate-live-data-to-your-website-with-python-f22b76699674
0 Response to "Using Python to Upload Data to Website"
Enregistrer un commentaire